Plugins
Built-in plugins
This is a list of built-in plugins that are considered stable.
See the Plugins section of the user guide for details on how built-in plugins are loaded.
reader.enclosure_dedupe
Deduplicate the enclosures of an entry by enclosure URL.
reader.entry_dedupe
Deduplicate the entries of a feed.
Sometimes, the format of the entry id changes for all the entries in a feed,
for example from example.com/123 to example.com/entry-title.
Because id uniquely identifies the entries of a feed,
this results in them being added again with the new ids.
entry_dedupe addresses this
by copying entry user attributes
like read or important from the old entries to the new one,
and deleting the old entries.
Duplicates are entries with the same title and the same summary/content.
By default, this plugin runs only for newly-added entries.
To run it for the existing entries of a feed,
add the .reader.dedupe.once tag to the feed;
the plugin will run on the next feed update, and remove the tag afterwards.
To run it for the existing entries in a feed,
and only use the title for comparisons (ignoring the content),
use .reader.dedupe.once.title instead.
Entry user attributes are set as follows:
If any of the entries is read/important, the new entry will be read/important.
read_modified / important_modified
Set to the oldest modified of the entries with the same status as the new read/important.
entry tags
For each tag key:
collect all the values from the duplicate entries
if the new entry does not have the tag, set it to the first value
copy the remaining values to the new entry, using a key of the form
.reader.duplicate.N.of.TAG, where N is an integer and TAG is the tag keyOnly unique values are considered, such that
TAG,.reader.duplicate.1.of.TAG,.reader.duplicate.2.of.TAG… always have different values.
To reduce false negatives when detecting duplicates:
All comparisons are case-insensitive, with HTML tags, HTML entities, punctuation, and whitespace removed.
For entries with content of different lengths, only a prefix of common (smaller) length is used in comparison. (This is useful when one version of an entry has only the first paragraph of the article, but the other has the whole article.)
For entries with longer content (over ~48 words), approximate matching is used instead of an exact match (currently, Jaccard similarity of 4-grams).
To reduce false positives when detecting duplicates:
Titles must match exactly (after clean-up).
Both entries must have title and content.
Similarity thresholds are set relatively high, and higher for shorter content.
Changelog
Changed in version 2.3: Delete old duplicates instead of marking them as read / unimportant.
Changed in version 2.2: Reduce false negatives by using approximate content matching.
Changed in version 2.2: Make it possible to re-run the plugin for existing entries.
reader.mark_as_read
Mark added entries of specific feeds as read + unimportant if their title matches a regex.
To configure, set the make_reader_reserved_name('mark-as-read')
(by default, .reader.mark-as-read)
tag to something like:
{
"title": ["first-regex", "second-regex"]
}
Changelog
Changed in version 2.7: Use the .reader.mark-as-read metadata for configuration.
Feeds using the old metadata, .reader.mark_as_read,
will be migrated automatically on update until reader 3.0.
Changed in version 2.4: Explicitly mark matching entries as unimportant.
reader.readtime
Calculate the read time for new/updated entries,
and store it as the .reader.readtime entry tag, with the format:
{'seconds': 1234}
The content used is that returned by get_content().
The read time for existing entries is backfilled as follows:
On the first
update_feeds()/update_feeds_iter()call:all feeds with
updates_disabledfalse are scheduled to be backfilledthe feeds selected to be updated are backfilled then
the feeds not selected to be updated will be backfilled the next time they are updated
all feeds with
updates_disabledtrue are backfilled, regardless of which feeds are selected to be updated
To prevent any feeds from being backfilled, set the
.reader.readtimeglobal tag to{'backfill': 'done'}.To schedule a feed to be backfilled on its next update, set the
.reader.readtimefeed tag to{'backfill': 'pending'}.
This plugin needs additional dependencies, use the readtime extra
to install them:
pip install reader[readtime]
Changelog
New in version 2.12.
reader.ua_fallback
Retry feed requests that get 403 Forbidden
with a different user agent.
Sometimes, servers blocks requests coming from reader based on the user agent. This plugin retries the request with feedparser’s user agent, which seems to be more widely accepted.
Servers/CDNs known to not accept the reader UA: Cloudflare, WP Engine.
Experimental plugins
reader also ships with a number of experimental plugins.
For these, the full entry point must be specified.
To use them from within Python code, use the entry point as a custom plugin:
>>> from reader._plugins import sqlite_releases
>>> reader = make_reader("db.sqlite", plugins=[sqlite_releases.init])
twitter
Create a feed out of a Twitter account.
Feed URLs must be of the of the form https://twitter.com/user (no query string).
In order to authenticate,
an OAuth 2.0 Bearer Token (app-only) is required
(corresponding Tweepy documentation);
set the value of the .reader.twitter global tag to:
{"token": "Bearer Token here"}
From within Python code:
key = reader.make_reader_reserved_name('twitter')
value = {"token": "Bearer Token here"}
reader.set_tag((), key, value)
Each entry in the feed corresponds to a thread;
currently, replies from other users are not included.
An HTML version of the thread is available
as a Content with type text/html;
the original JSON data is also available with type application/x.twitter+json.
On the first update, up to 1,000 tweets are retrieved; on subsequent updates, only new tweets are retrieved (for reference, Essential access caps at 500K tweets per month). When a new tweet is published in an existing thread, the corresponding entry is updated accordingly.
The HTML content can be rerendered from the existing JSON data
by adding the .reader.twitter.rerender tag to the feed;
on the next feed update, the plugin will rerender the HTML content
and remove the tag.
Screenshots:
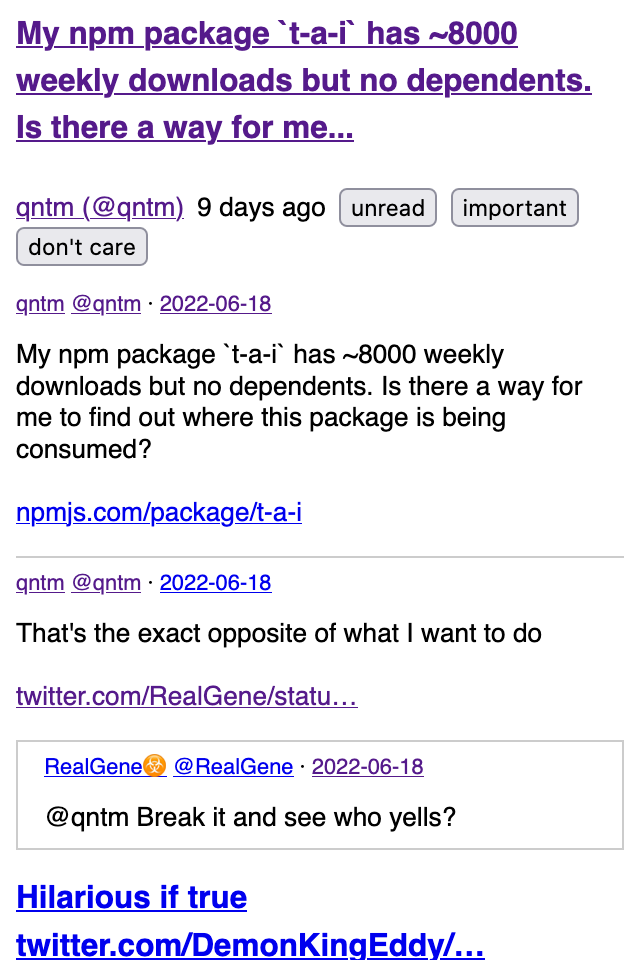
To do (roughly in order of importance):
retrieve media/polls in quoted/retweeted tweet
media URL might be None
retrieve retweets/quotes of retweets/quotes
handle deleted tweets in conversations (currently leads to truncated/missing conversation)
lower the initial tweet limit, but allow increasing it
automatically re-render entry HTML on plugin update
show images / expanded URLs only in the original tweet, not in retweets
mark updated entries as unread
better URL/entity expansion (feed subtitle, entry hashtags and usernames)
better media rendering
better poll rendering
retrieve and render tweet replies (
https://twitter.com/user?replies=yes)support previewing Twitter feeds in the web app
This plugin needs additional dependencies, use the unstable-plugins extra
to install them:
pip install reader[unstable-plugins]
To load:
READER_PLUGIN='reader._plugins.twitter:init_reader' \
python -m reader ...
cli_status
Capture the stdout of a CLI command and add it as an entry to a special feed.
The feed URL is reader:status; if it does not exist, it is created.
The entry id is the command, without options or arguments:
('reader:status', 'command: update')
('reader:status', 'command: search update')
Entries are marked as read.
To load:
READER_CLI_PLUGIN='reader._plugins.cli_status.init_cli' \
python -m reader ...
preview_feed_list
If the feed to be previewed is not actually a feed, show a list of feeds linked from that URL (if any).
This plugin needs additional dependencies, use the unstable-plugins extra
to install them:
pip install reader[unstable-plugins]
To load:
READER_APP_PLUGIN='reader._plugins.preview_feed_list:init' \
python -m reader serve
Implemented for https://github.com/lemon24/reader/issues/150.
sqlite_releases
Create a feed out of the SQLite release history pages at:
Also serves as an example of how to write custom parsers.
This plugin needs additional dependencies, use the unstable-plugins extra
to install them:
pip install reader[unstable-plugins]
To load:
READER_PLUGIN='reader._plugins.sqlite_releases:init' \
python -m reader ...
tumblr_gdpr
Accept Tumblr GDPR stuff.
Since May 2018, Tumblr redirects all new sessions to an “accept the terms of service” page, including RSS feeds (supposed to be machine-readable), breaking them.
This plugin “accepts the terms of service” on your behalf.
To load:
READER_PLUGIN='reader._plugins.tumblr_gdpr:tumblr_gdpr' \
python -m reader update -v
Implemented for https://github.com/lemon24/reader/issues/67.
Note
This plugin does not seem to be needed anymore as of August 2020.
Loading plugins from the CLI and the web application
There is experimental support of plugins in the CLI and the web application.
Warning
The plugin system/hooks are not stable yet and may change without any notice.
To load plugins, set the READER_PLUGIN environment variable to the plugin
entry point (e.g. package.module:entry_point); multiple entry points should
be separated by one space:
READER_PLUGIN='first.plugin:entry_point second_plugin:main' \
python -m reader some-command
For built-in plugins, it is enough to use the plugin name (reader.XYZ).
Note
make_reader() ignores the plugin environment variables.
To load web application plugins, set the READER_APP_PLUGIN environment variable.
To load CLI plugins (that customize the CLI),
set the READER_CLI_PLUGIN environment variable.